
On this weblog put up, we’ll discover:
- Issues with conventional LLMs
- What’s Retrieval-Augmented Technology (RAG)?
- How RAG works
- Actual-world implementations of RAG
Issues With Conventional LLMs
Whereas LLMS have revolutionized the best way we work together with expertise, they arrive with some vital limitations:
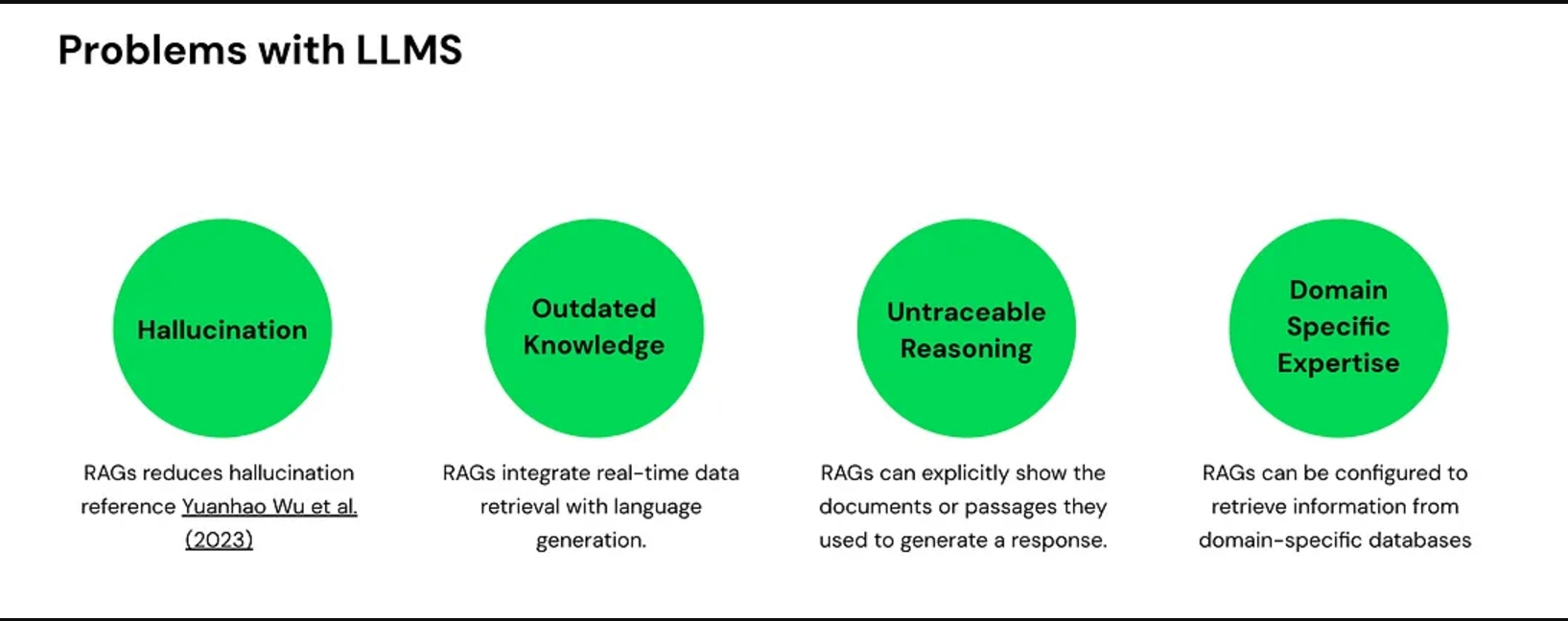
Hallucination
LLMs generally hallucinate, which means they supply factually incorrect solutions. This happens as a result of they generate responses based mostly on patterns within the knowledge they have been educated on, not all the time on verified details.
- Instance: An AI would possibly state {that a} historic occasion occurred in a 12 months when it didn’t.
Outdated Data
Fashions like GPT-4 have a information cutoff date (e.g., Might 2024). They lack info on occasions or developments that occurred after this date.
- Implication: The AI can’t present insights on latest developments, information, or knowledge.
Untraceable Reasoning
LLMs typically present solutions with out clear sources, resulting in untraceable reasoning.
- Transparency: Customers don’t know the place the knowledge got here from.
- Bias: The coaching knowledge might comprise biases, affecting the output.
- Accountability: Tough to confirm the accuracy of the response
Lack of Area-Particular Experience
Whereas LLMs are good at producing normal responses, they typically lack domain-specific experience.
- Consequence: Solutions could also be generic and never delve deep into specialised matters.
Issues with LLM
What Is RAG?
Think about RAG as your private assistant who can memorize hundreds of pages of paperwork. You may later question this assistant to extract any info you want.
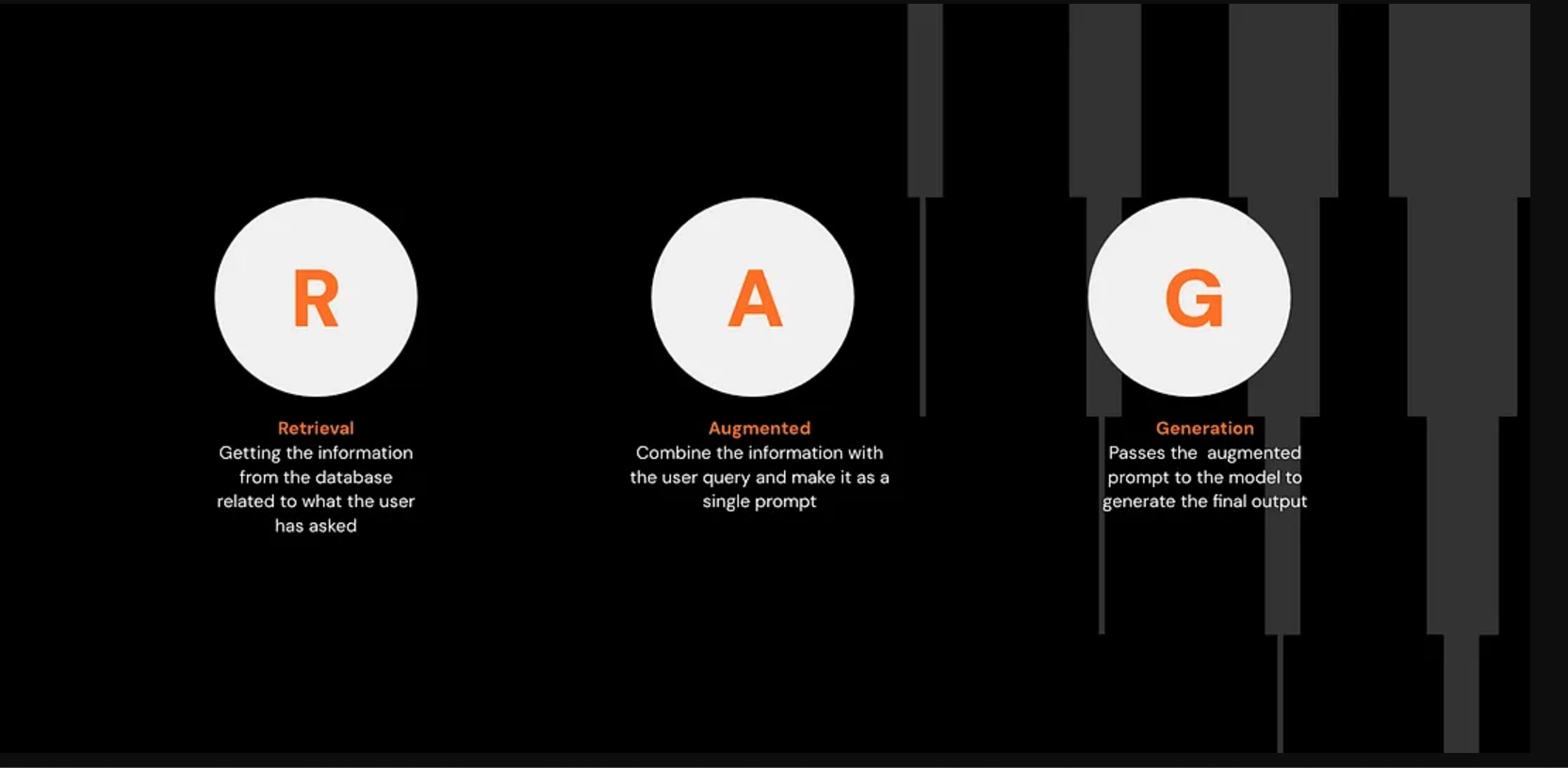
RAG stands for Retrieval-Augmented Technology, the place:
- Retrieval: Fetches info from a database
- Augmentation: Combines the retrieved info with the consumer’s immediate
- Technology: Produces the ultimate reply utilizing an LLM
How RAG Works: The Conventional Methodology vs. RAG
Conventional LLM Strategy
- A consumer asks a query.
- The LLM generates a solution based mostly solely on its educated information base.
- If the query is outdoors its information base, it could present incorrect or generic solutions.
RAG Strategy
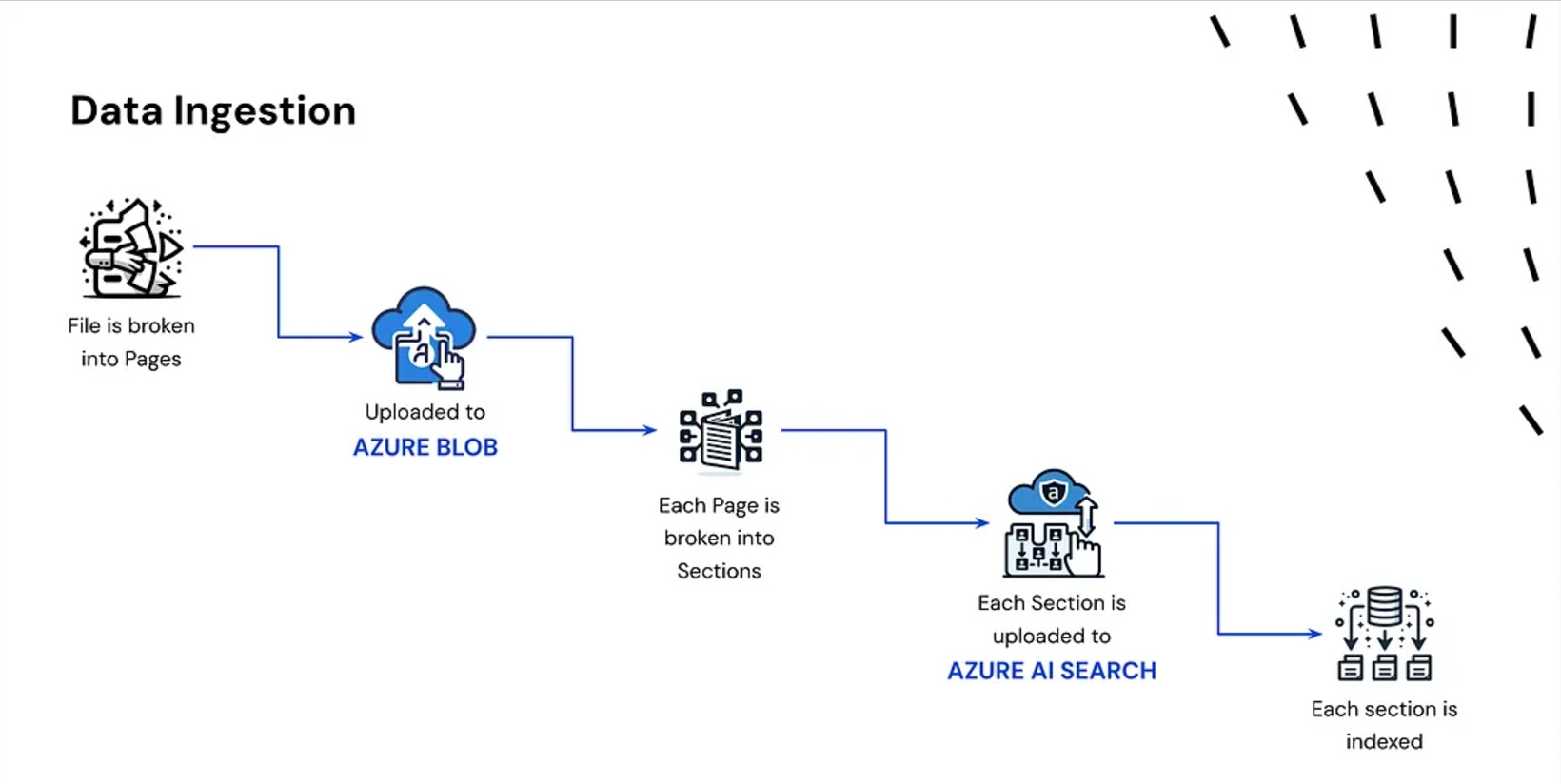
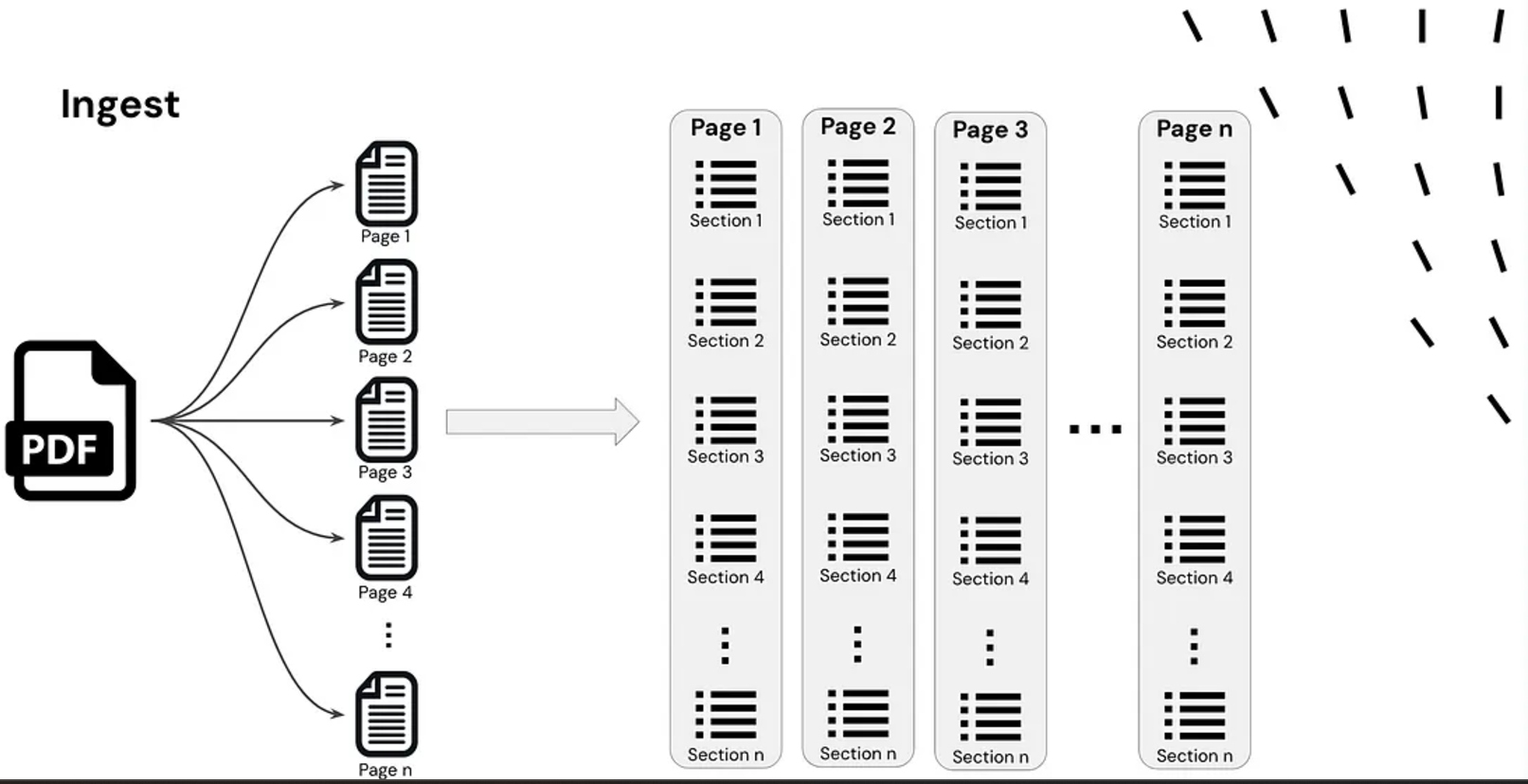
1. Doc Ingestion
- A doc is damaged down into smaller chunks.
- These chunks are transformed into embeddings (vector representations).
- The embeddings are listed and saved in a vector database.
2. Question Processing
- The consumer asks a query.
- The query is transformed into an embedding utilizing the identical mannequin.
- A search engine queries the vector database to seek out essentially the most related chunks.
- The highest related outcomes are retrieved.
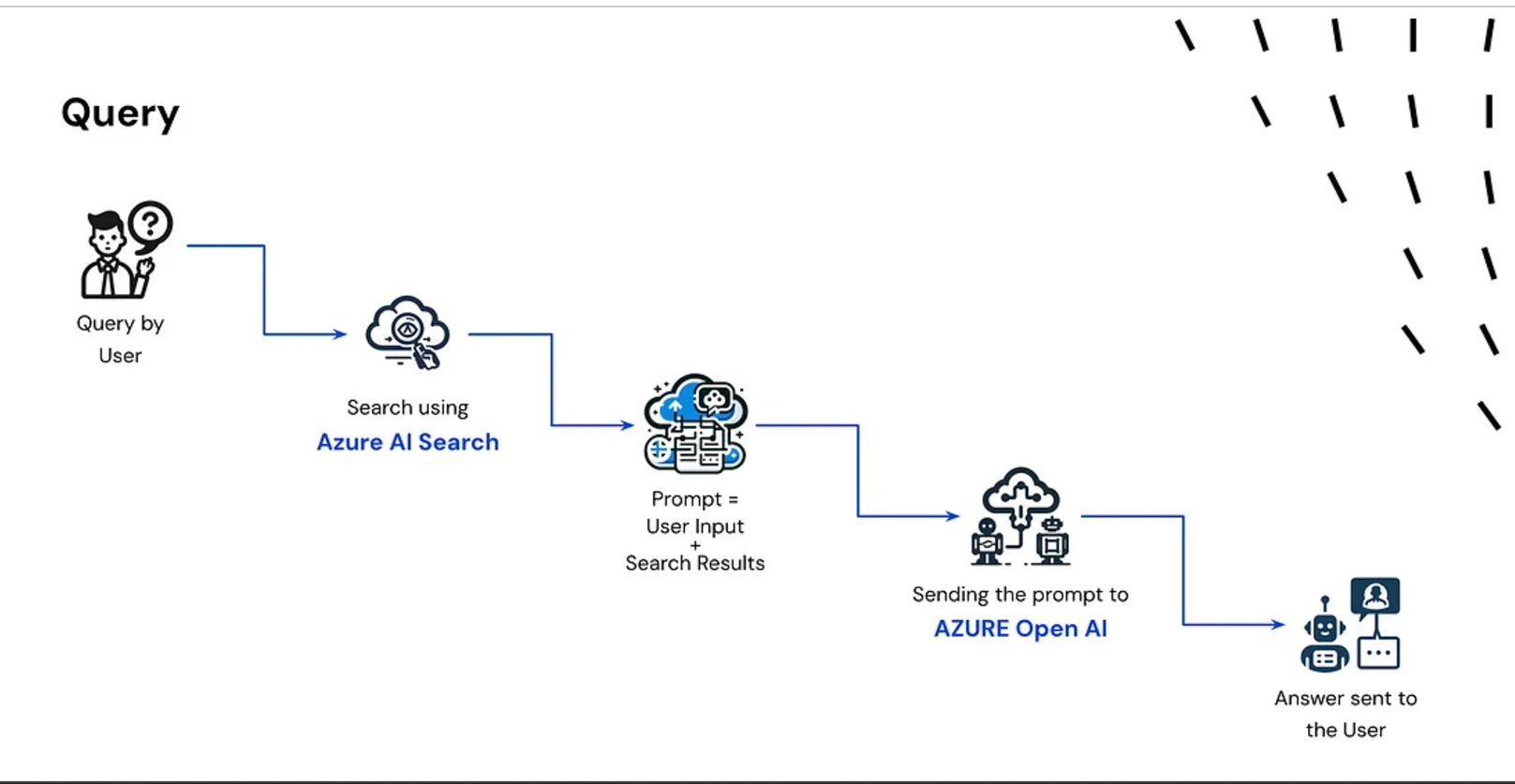

3. Reply Technology
- The retrieved info and the consumer’s query are mixed.
- This mixed enter is handed to the LLM (like GPT-4 or LLaMA).
- The LLM generates a context-aware reply.
- The reply is returned to the consumer.
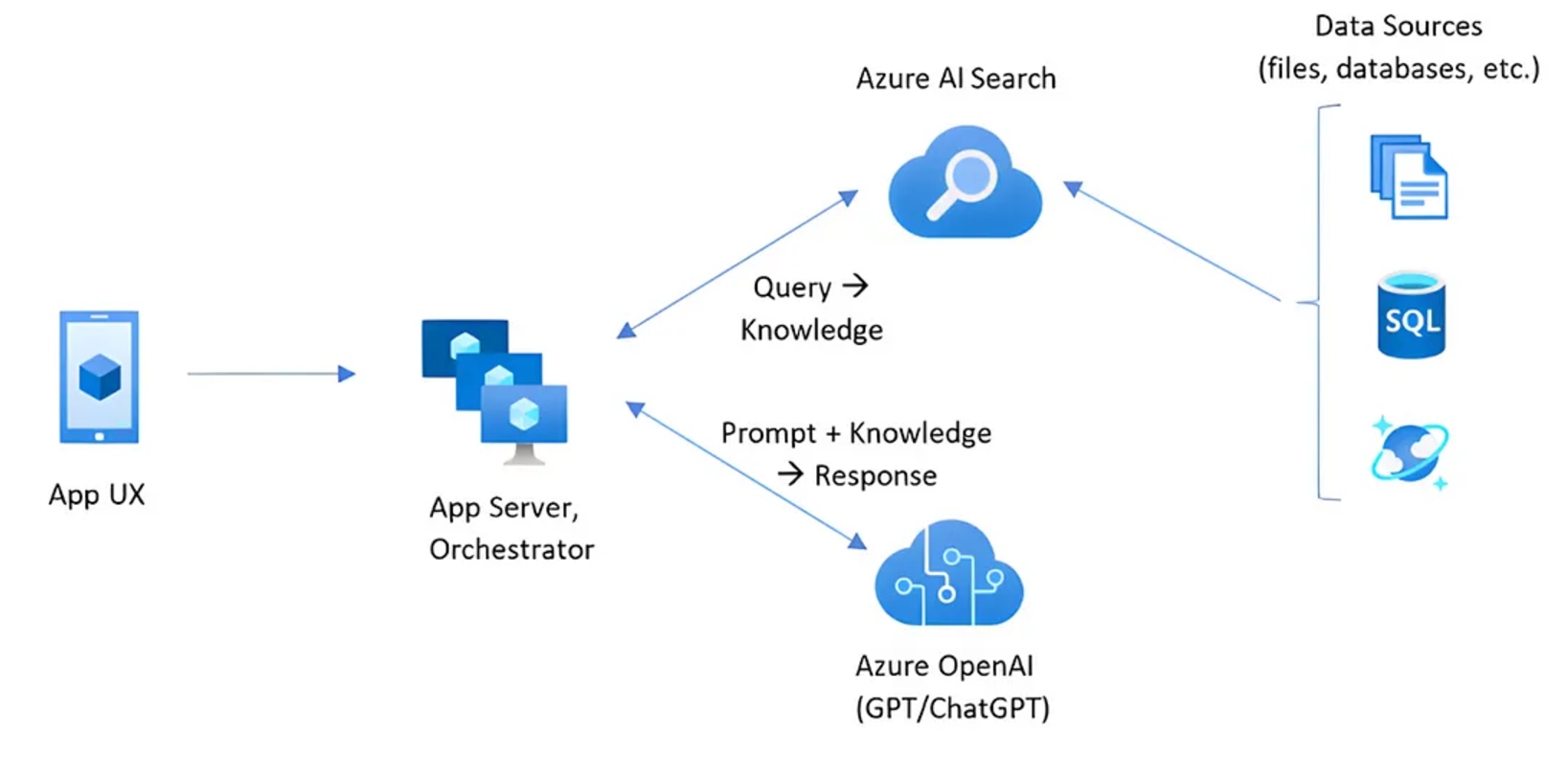
Actual-World Implementations of RAG
Basic Data Retrieval
- Enter in depth paperwork (a whole lot or hundreds of pages)
- Effectively extract particular info when wanted
Buyer Help
- RAG-powered chatbots can entry real-time buyer knowledge.
- Present correct and personalised responses in sectors like finance, banking, or telecom
- Improved first-response charges result in larger buyer satisfaction and loyalty
Authorized Sector
- Help in contract evaluation, e-discoveries, or regulatory compliances
- Streamline authorized analysis and doc assessment processes
Video
Conclusion
As Thomas Edison as soon as stated:
“Imaginative and prescient with out execution is hallucination.”
Within the context of AI:
“LLMs with out RAG are hallucination.”

By integrating RAG, we are able to overcome many limitations of conventional LLMs, offering extra correct, up-to-date, and domain-specific solutions.
In upcoming posts, we’ll discover extra superior matters on RAG and methods to acquire much more related responses from it. Keep tuned!
Thanks for studying!









{kind=link}