
[ad_1]
As builders, we all the time search for methods to make our growth workflows smoother and extra environment friendly. With the brand new 12 months unfolding, the panorama of AI-powered code assistants is evolving at a fast tempo. It’s projected that, by 2028, 75% of enterprise software program engineers will use AI code assistants, a monumental leap from lower than 10% in early 2023. Instruments like GitHub Copilot, ChatGPT, and Amazon CodeWhisperer have already made vital inroads.
Nevertheless, whereas these instruments are spectacular, they typically function as one-size-fits-all options. The true magic occurs after we take management of their workflows, creating clever, context-aware assistants tailor-made to our distinctive wants. That is the place Retrieval-augmented eneration (RAG) can come in useful.
At its core, RAG is about combining two highly effective concepts: trying to find the best data (retrieval) and utilizing AI to generate significant and context-aware responses (era). Consider it like having a supercharged assistant that is aware of the right way to discover the solutions you want and clarify them in a method that is sensible.
What Are We Constructing?
On this tutorial, we’ll construct a code assistant that mixes the perfect of recent AI strategies:
- Retrieval-augmented era (RAG) for correct, context-aware responses
- LangChain for sturdy AI pipelines
- Native mannequin execution with Ollama
Understanding the Constructing Blocks
Earlier than we begin coding, let’s perceive what makes our assistant particular. We’re combining three highly effective concepts:
- RAG (Retrieval-Augmented Era): Consider this like giving our AI assistant a sensible pocket book. If you ask a query, it first seems up related data (retrieval) earlier than crafting a solution (era). This implies it all the time solutions primarily based in your precise code, not simply basic information.
- LangChain: That is our AI toolkit that helps join totally different items easily. It is like having a well-organized workshop the place all our instruments work collectively completely.
- Ollama: That is our native AI powerhouse. Ollama lets us run highly effective language fashions proper on our personal computer systems as an alternative of counting on distant servers. Consider it as having an excellent coding assistant sitting proper at your desk somewhat than having to make a cellphone name each time you need assistance. This implies sooner responses, higher privateness (since your code stays in your machine), and no want to fret about web connectivity. Ollama makes it straightforward to run fashions like Llama 2 domestically, which might in any other case require a posh setup and vital computational assets.
Stipulations
To comply with alongside, guarantee you’ve the next:
- Primary information of Python programming
- Python 3.8+ put in in your system
- An IDE or code editor (e.g., VS Code, PyCharm)
Setting Up the Atmosphere
Step 1: Create Challenge Construction
First, let’s arrange our venture listing:
mkdir rag_code_assistant
cd rag_code_assistant
mkdir code_snippetsStep 2: Set up Dependencies
Set up all required packages utilizing pip:
pip set up langchain-community langchain-openai langchain-ollama colorama faiss-cpuThese packages serve totally different functions:
langchain-community: Supplies core performance for doc loading and vector shopslangchain-openai: Handles OpenAI embeddings integrationlangchain-ollama: Permits native LLM utilization by Ollamacolorama: Provides coloured output to our terminal interfacefaiss-cpu: Powers our vector similarity search
Step 3: Set up and Begin Ollama
- Obtain Ollama from https://ollama.ai/download
- Set up it following the directions on your working system
- Begin the Ollama server:
Step 4: Create Information Base
Within the code_snippets folder, create calculator.py:
def add_numbers(a, b):
return a + b
def subtract_numbers(a, b):
return a - b
def multiply_numbers(a, b):
return a * b
def divide_numbers(a, b):
if b != 0:
return a / b
return "Division by zero error"Constructing the RAG Assistant
Step 1: Create the Index Information Base (index_knowledge_base.py)
from langchain_community.document_loaders import DirectoryLoader
from langchain_community.vectorstores import FAISS
from langchain_openai.embeddings import OpenAIEmbeddings
from colorama import Fore, Type, init
# Initialize colorama for terminal colour assist
init(autoreset=True)
def create_index():
openai_api_key = "your-openai-api-key" # Change along with your precise API key
attempt:
print(f"{Fore.LIGHTBLUE_EX}Loading paperwork from the 'code_snippets' folder...{Type.RESET_ALL}")
loader = DirectoryLoader("code_snippets", glob="**/*.py")
paperwork = loader.load()
print(f"{Fore.LIGHTGREEN_EX}Paperwork loaded efficiently!{Type.RESET_ALL}")
print(f"{Fore.LIGHTBLUE_EX}Indexing paperwork...{Type.RESET_ALL}")
data_store = FAISS.from_documents(paperwork, OpenAIEmbeddings(openai_api_key=openai_api_key))
data_store.save_local("index")
print(f"{Fore.LIGHTGREEN_EX}Information base listed efficiently!{Type.RESET_ALL}")
besides Exception as e:
print(f"{Fore.RED}Error in creating index: {e}{Type.RESET_ALL}")This script does a number of essential issues:
- Makes use of DirectoryLoader to learn Python recordsdata from our
code_snippetsfolder - Converts the code into embeddings utilizing OpenAI’s embedding mannequin
- Shops these embeddings in a FAISS index for fast retrieval
- Provides coloured output for higher person expertise
Step 2: Create the Retrieval Pipeline (retrieval_pipeline.py)
from langchain_community.vectorstores import FAISS
from langchain_openai.embeddings import OpenAIEmbeddings
from langchain_ollama.llms import OllamaLLM
from colorama import Fore, Type, init
import asyncio
# Initialize colorama for terminal colour assist
init(autoreset=True)
openai_api_key = "your-openai-api-key" # Change along with your precise API key
attempt:
print(f"{Fore.LIGHTYELLOW_EX}Loading FAISS index...{Type.RESET_ALL}")
data_store = FAISS.load_local(
"index",
OpenAIEmbeddings(openai_api_key=openai_api_key),
allow_dangerous_deserialization=True
)
print(f"{Fore.LIGHTGREEN_EX}FAISS index loaded efficiently!{Type.RESET_ALL}")
besides Exception as e:
print(f"{Fore.RED}Error loading FAISS index: {e}{Type.RESET_ALL}")
attempt:
print(f"{Fore.LIGHTYELLOW_EX}Initializing the Ollama LLM...{Type.RESET_ALL}")
llm = OllamaLLM(mannequin="llama3.2", base_url="http://localhost:11434", timeout=120)
print(f"{Fore.LIGHTGREEN_EX}Ollama LLM initialized efficiently!{Type.RESET_ALL}")
besides Exception as e:
print(f"{Fore.RED}Error initializing Ollama LLM: {e}{Type.RESET_ALL}")
def query_pipeline(question):
attempt:
print(f"{Fore.LIGHTBLUE_EX}Looking out the information base...{Type.RESET_ALL}")
context = data_store.similarity_search(question)
print(f"{Fore.LIGHTGREEN_EX}Context discovered:{Type.RESET_ALL} {context}")
immediate = f"Context: {context}nQuestion: {question}"
print(f"{Fore.LIGHTBLUE_EX}Sending immediate to LLM...{Type.RESET_ALL}")
response = llm.generate(prompts=[prompt])
print(f"{Fore.LIGHTGREEN_EX}Acquired response from LLM.{Type.RESET_ALL}")
return response
besides Exception as e:
print(f"{Fore.RED}Error in question pipeline: {e}{Type.RESET_ALL}")
return f"{Fore.RED}Unable to course of the question. Please attempt once more.{Type.RESET_ALL}"This pipeline:
- Masses our beforehand created FAISS index
- Initializes the Ollama LLM for native inference
- Implements the question perform that:
- Searches for related code context
- Combines it with the person’s question
- Generates a response utilizing the native LLM
Step 3: Create the Interactive Assistant (interactive_assistant.py)
from retrieval_pipeline import query_pipeline
from colorama import Fore, Type, init
# Initialize colorama for terminal colour assist
init(autoreset=True)
def interactive_mode():
print(f"{Fore.LIGHTBLUE_EX}Begin querying your RAG assistant. Kind 'exit' to stop.{Type.RESET_ALL}")
whereas True:
attempt:
question = enter(f"{Fore.LIGHTGREEN_EX}Question: {Type.RESET_ALL}")
if question.decrease() == "exit":
print(f"{Fore.LIGHTBLUE_EX}Exiting... Goodbye!{Type.RESET_ALL}")
break
print(f"{Fore.LIGHTYELLOW_EX}Processing your question...{Type.RESET_ALL}")
response = query_pipeline(question)
print(f"{Fore.LIGHTCYAN_EX}Assistant Response: {Type.RESET_ALL}{response.generations[0][0].textual content}")
besides Exception as e:
print(f"{Fore.RED}Error in interactive mode: {e}{Type.RESET_ALL}")The interactive assistant:
- Creates a user-friendly interface for querying
- Handles the interplay loop
- Supplies coloured suggestions for several types of messages
Step 4: Create the Fundamental Script (principal.py)
from interactive_assistant import interactive_mode
from index_knowledge_base import create_index
from colorama import Fore, Type, init
# Initialize colorama for terminal colour assist
init(autoreset=True)
print(f"{Fore.LIGHTBLUE_EX}Initializing the RAG-powered Code Assistant...{Type.RESET_ALL}")
attempt:
print(f"{Fore.LIGHTYELLOW_EX}Indexing the information base...{Type.RESET_ALL}")
create_index()
print(f"{Fore.LIGHTGREEN_EX}Information base listed efficiently!{Type.RESET_ALL}")
besides Exception as e:
print(f"{Fore.RED}Error whereas indexing the information base: {e}{Type.RESET_ALL}")
attempt:
print(f"{Fore.LIGHTYELLOW_EX}Beginning the interactive assistant...{Type.RESET_ALL}")
interactive_mode()
besides Exception as e:
print(f"{Fore.RED}Error in interactive assistant: {e}{Type.RESET_ALL}")The principle script orchestrates all the course of:
- Creates the information base index
- Launches the interactive assistant
- Handles any errors that may happen
Operating the Assistant
Ensure your Ollama server is operating:
Change the OpenAI API key in each index_knowledge_base.py and retrieval_pipeline.py along with your precise key
Run the assistant:
Now you can ask questions on your code! For instance:
- “How does the calculator deal with division by zero?”
- “What mathematical operations can be found?”
- “Present me the implementation of multiplication”
Output:
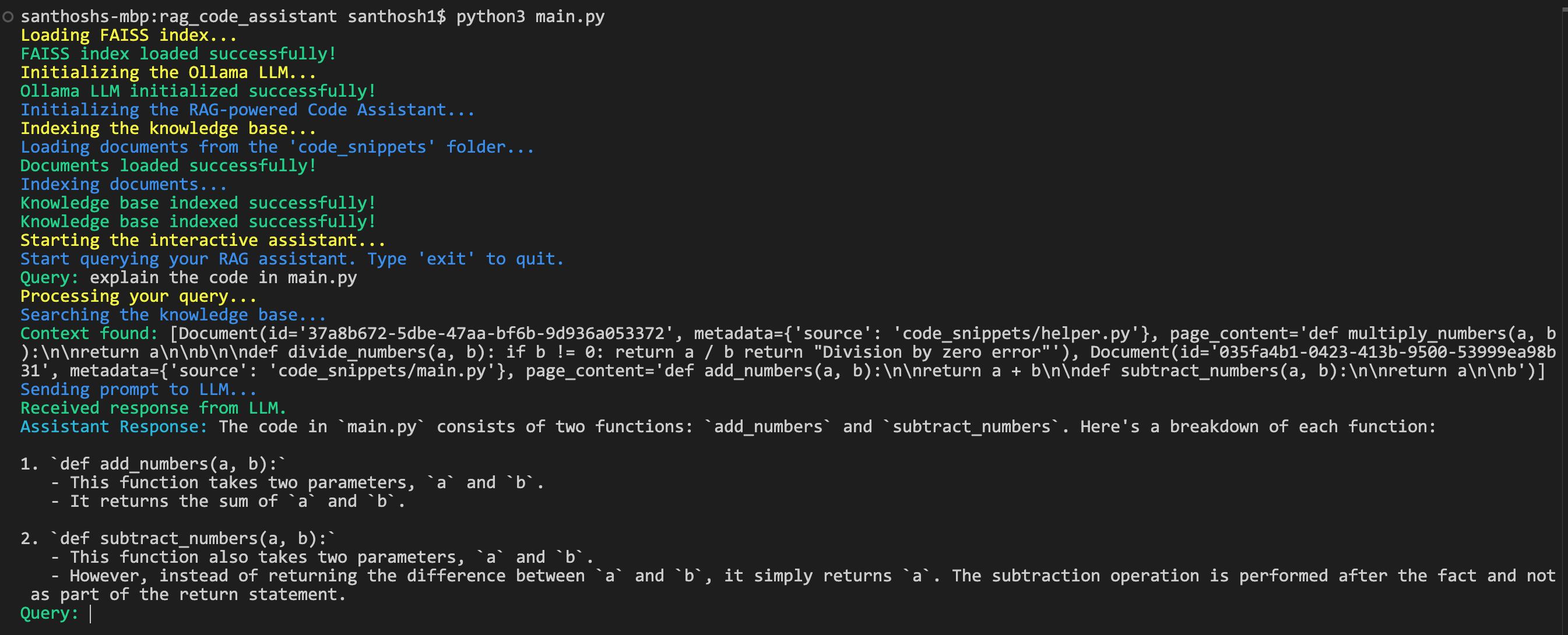
Conclusion
Constructing a RAG-powered code assistant isn’t nearly making a device — it’s about taking possession of your workflow and making your growth course of not simply extra environment friendly however truly extra gratifying. Positive, there are many AI-powered instruments on the market, however this hands-on method helps you to construct one thing that’s actually yours — tailor-made to your actual wants and preferences.
Alongside the best way, you’ve picked up some fairly cool abilities: establishing a information base, indexing it with LangChain, and crafting a retrieval and era pipeline with Ollama. These are the constructing blocks of making clever, context-aware instruments that may make an actual distinction in how you’re employed.
[ad_2]
