
In MuleSoft functions working in multi-threaded or multi-worker environments, the chance of parallel writing points arises when a number of threads or staff try and entry or replace the identical shared useful resource concurrently. These points can result in knowledge corruption, inconsistencies, or sudden habits, particularly in distributed methods the place Mule functions are deployed throughout a number of staff in a cluster.
The Drawback: Parallel Writing
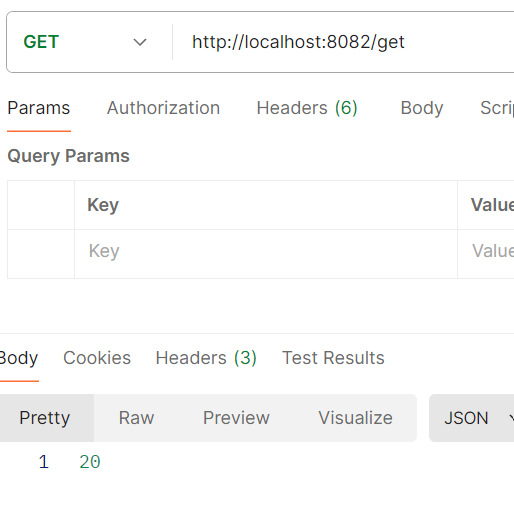
Let me illustrate the issue first. I created a easy counter application that helps /inc and /get operations. The /inc operation will increase the counter by 1, and the /get operation returns the present worth.
Now, if I hit /inc parallelly from JMeter 300 occasions, the /get ought to return precisely 300 if all writes are profitable and no overwrite occurs. Nonetheless, in Mule4, we won’t get 300.
Concern: Decrease Depend Because of Overwriting
The screenshot reveals we’re getting a a lot decrease quantity right here due to parallel threads, which ends up in overwriting.
The Answer: Distributed Locking in Mule 4
To resolve this difficulty, Mule 3 supplied the “retrieve-with-lock” object store operation (<objectstore:retrieve-with-lock>). Nonetheless, Mule 4 doesn’t provide this out-of-the-box resolution. As a substitute, Mule 4 requires distributed locking by way of LockFactory.createLock().
The counter application version 2 makes use of a Groovy script and Java bean to implement distributed locking. The Groovy script may be very small, and it performs solely the bean lookup and technique invocation:






![RAG From a Newbie to Superior: Introduction [Video]](https://toptechstocks.com/wp-content/uploads/2024/12/18089976-thumb-120x86.jpg)


{kind=link}