
Editor’s Be aware: The next is an article written for and printed in DZone’s 2024 Development Report, Data Engineering: Enriching Data Pipelines, Expanding AI, and Expediting Analytics.
Information engineering and software program engineering have lengthy been at odds, every with their very own distinctive instruments and greatest practices. A key differentiator has been the necessity for devoted orchestration when constructing information merchandise. On this article, we’ll discover the position information orchestrators play and the way latest developments within the business could also be bringing these two disciplines nearer collectively than ever earlier than.
The State of Information Orchestration
One of many main targets of investing in information capabilities is to unify data and understanding throughout the enterprise. The worth of doing so might be immense, however it includes integrating a rising variety of programs with typically rising complexity. Information orchestration serves to supply a principled strategy to composing these programs, with complexity coming from:
- Many distinct sources of information, every with their very own semantics and limitations
- Many locations, stakeholders, and use instances for information merchandise
- Heterogeneous instruments and processes concerned with creating the top product
There are a number of parts in a typical information stack that assist set up these widespread eventualities.
The Elements
The prevailing business sample for information engineering is named extract, load, and remodel, or ELT. Information is (E) extracted from upstream sources, (L) loaded straight into the information warehouse, and solely then (T) reworked into varied domain-specific representations. Variations exist, similar to ETL, which performs transformations earlier than loading into the warehouse. What all approaches have in widespread are three high-level capabilities: ingestion, transformation, and serving. Orchestration is required to coordinate between these three levels, but additionally inside each as nicely.
Ingestion
Ingestion is the method that strikes information from a supply system (e.g., database), right into a storage system that enables transformation levels to extra simply entry it. Orchestration at this stage sometimes includes scheduling duties to run when new information is anticipated upstream or actively listening for notifications from these programs when it turns into out there.
Transformation
Widespread examples of transformations embody unpacking and cleansing information from its unique construction in addition to splitting or becoming a member of it right into a mannequin extra intently aligned with the enterprise area. SQL and Python are the commonest methods to precise these transformations, and fashionable information warehouses present glorious help for them. The position of orchestration on this stage is to sequence the transformations in an effort to effectively produce the fashions utilized by stakeholders.
Serving
Serving can discuss with a really broad vary of actions. In some instances, the place the top person can work together straight with the warehouse, this may increasingly solely contain information curation and entry management. Extra typically, downstream purposes want entry to the information, which, in flip, requires synchronization with the warehouse’s fashions. Loading and synchronization is the place orchestrators play a job within the serving stage.
Determine 1. Typical stream of information from sources, by means of the information warehouse, out to end-user apps
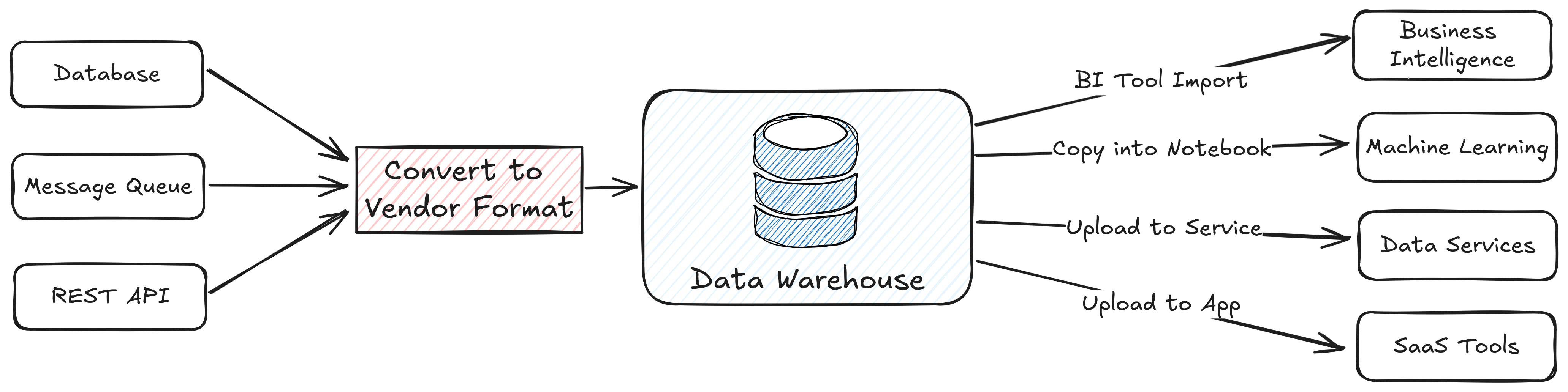
Ingestion brings information in, transformation happens within the warehouse, and information is served to downstream apps.
These three levels comprise a helpful psychological mannequin for analyzing programs, however what’s essential to the enterprise is the capabilities they permit. Information orchestration helps coordinate the processes wanted to take information from supply programs, that are probably a part of the core enterprise, and switch it into information merchandise. These processes are sometimes heterogeneous and weren’t essentially constructed to work collectively. This will put quite a lot of accountability on the orchestrator, tasking it with making copies, changing codecs, and different advert hoc actions to deliver these capabilities collectively.
The Instruments
At their core, most information programs depend on some scheduling capabilities. When solely a restricted variety of providers should be managed on a predictable foundation, a standard strategy is to make use of a easy scheduler similar to cron. Duties coordinated on this means might be very loosely coupled. Within the case of job dependencies, it’s easy to schedule one to start out a while after the opposite is anticipated to complete, however the consequence might be delicate to sudden delays and hidden dependencies.
As processes develop in complexity, it turns into beneficial to make dependencies between them express. That is what workflow engines similar to Apache Airflow present. Airflow and comparable programs are additionally sometimes called “orchestrators,” however as we’ll see, they aren’t the one strategy to orchestration. Workflow engines allow information engineers to specify express orderings between duties. They help working scheduled duties very like cron and also can look ahead to exterior occasions that ought to set off a run. Along with making pipelines extra sturdy, the chicken’s-eye view of dependencies they provide can enhance visibility and allow extra governance controls.
Generally the notion of a “job” itself might be limiting. Duties will inherently function on batches of information, however the world of streaming depends on items of information that stream repeatedly. Many fashionable streaming frameworks are constructed across the dataflow mannequin — Apache Flink being a preferred instance. This strategy forgoes the sequencing of unbiased duties in favor of composing fine-grained computations that may function on chunks of any dimension.
From Orchestration to Composition
The widespread thread between these programs is that they seize dependencies, be it implicit or express, batch or streaming. Many programs would require a mix of those methods, so a constant mannequin of information orchestration ought to take all of them under consideration. That is provided by the broader idea of composition that captures a lot of what information orchestrators do right now and in addition expands the horizons for a way these programs might be constructed sooner or later.
Composable Information Programs
The way forward for information orchestration is transferring towards composable information programs. Orchestrators have been carrying the heavy burden of connecting a rising variety of programs that had been by no means designed to work together with each other. Organizations have constructed an unbelievable quantity of “glue” to carry these processes collectively. By rethinking the assumptions of how information programs match collectively, new approaches can enormously simplify their design.
Open Requirements
Open requirements for information codecs are on the heart of the composable information motion. Apache Parquet has turn out to be the de facto file format for columnar information, and Apache Arrow is its in-memory counterpart. The standardization round these codecs is essential as a result of it reduces and even eliminates the expensive copy, convert, and switch steps that plague many information pipelines. Integrating with programs that help these codecs natively allows native “information sharing” with out all of the glue code. For instance, an ingestion course of may write Parquet information to object storage after which merely share the trail to these information. Downstream providers can then entry these information with no need to make their very own inside copies. If a workload must share information with a neighborhood course of or a distant server, it might use Arrow IPC or Arrow Flight with near zero overhead.
Standardization is occurring in any respect ranges of the stack. Apache Iceberg and different open desk codecs are constructing upon the success of Parquet by defining a structure for organizing information in order that they are often interpreted as tables. This provides delicate however essential semantics to file entry that may flip a group of information right into a principled data lakehouse. Coupled with a catalog, such because the lately incubating Apache Polaris, organizations have the governance controls to construct an authoritative supply of reality whereas benefiting from the zero-copy sharing that the underlying codecs allow. The ability of this mix can’t be overstated. When the enterprise’ supply of reality is zero-copy suitable with the remainder of the ecosystem, a lot orchestration might be achieved just by sharing information as an alternative of constructing cumbersome connector processes.
Determine 2. A knowledge system composed of open requirements
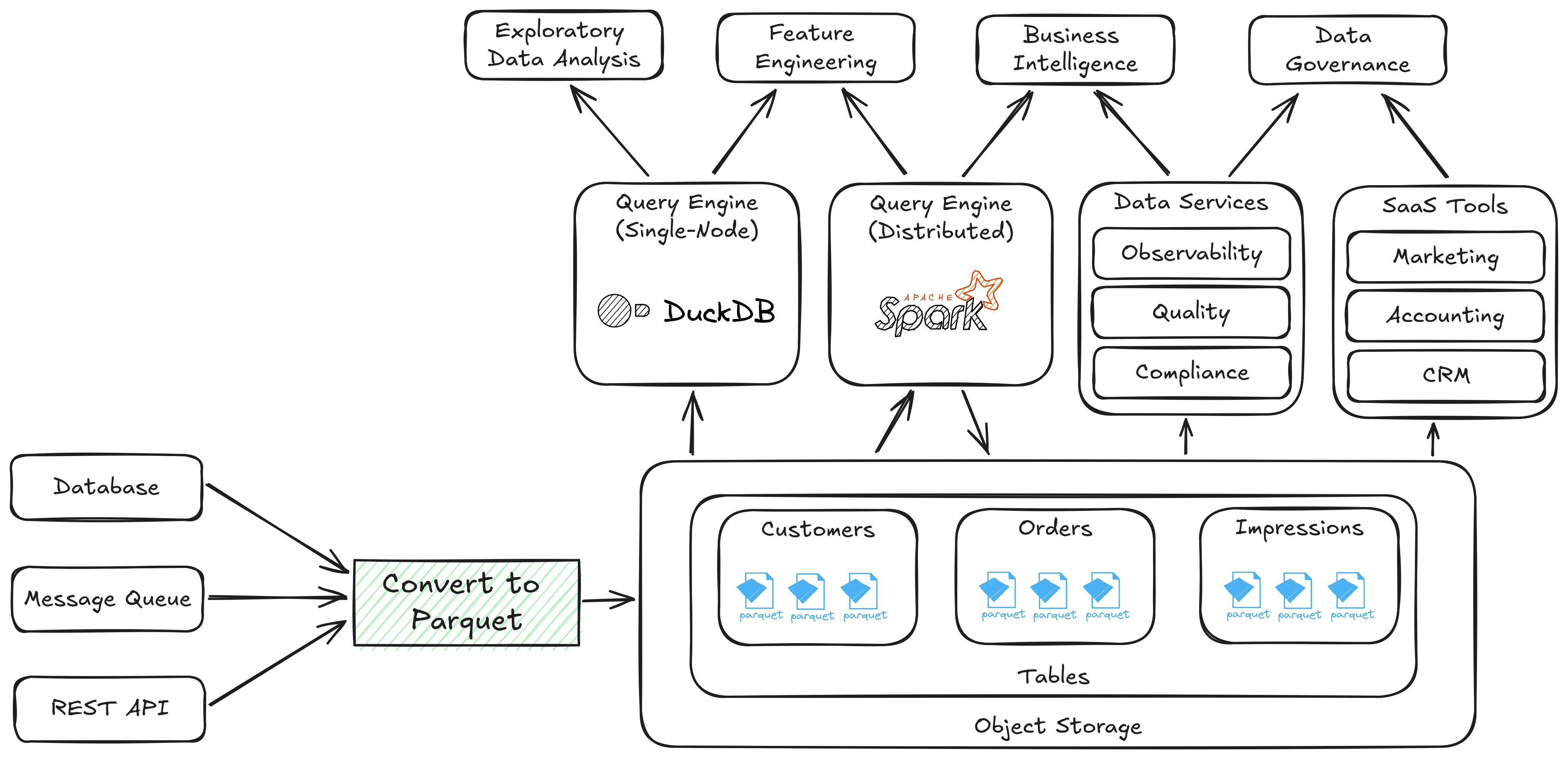
As soon as information is written to object storage as Parquet, it may be shared with none conversions.
The Deconstructed Stack
Information programs have all the time wanted to make assumptions about file, reminiscence, and desk codecs, however normally, they have been hidden deep inside their implementations. A slender API for interacting with a knowledge warehouse or information service vendor makes for clear product design, however it doesn’t maximize the alternatives out there to finish customers. Think about Determine 1 and Determine 2, which depict information programs aiming to help comparable enterprise capabilities.
In a closed system, the information warehouse maintains its personal desk construction and question engine internally. This can be a one-size-fits-all strategy that makes it simple to get began however might be tough to scale to new enterprise necessities. Lock-in might be arduous to keep away from, particularly with regards to capabilities like governance and different providers that entry the information. Cloud suppliers provide seamless and environment friendly integrations inside their ecosystems as a result of their inside information format is constant, however this may increasingly shut the door on adopting higher choices outdoors that setting. Exporting to an exterior supplier as an alternative requires sustaining connectors purpose-built for the warehouse’s proprietary APIs, and it might result in information sprawl throughout programs.
An open, deconstructed system standardizes its lowest-level particulars. This permits companies to choose and select the very best vendor for a service whereas having the seamless expertise that was beforehand solely potential in a closed ecosystem. In apply, the chief concern of an open information system is to first copy, convert, and land supply information into an open desk format. As soon as that’s completed, a lot orchestration might be achieved by sharing references to information that has solely been written as soon as to the group’s supply of reality. It’s this transfer towards information sharing in any respect ranges that’s main organizations to rethink the way in which that information is orchestrated and construct the information merchandise of the longer term.
Conclusion
Orchestration is the spine of recent information programs. In lots of companies, it’s the core know-how tasked with untangling their complicated and interconnected processes, however new developments in open requirements are providing a contemporary tackle how these dependencies might be coordinated. As a substitute of pushing larger complexity into the orchestration layer, programs are being constructed from the bottom as much as share information collaboratively. Cloud suppliers have been including compatibility with these requirements, which helps pave the way in which for the best-of-breed options of tomorrow. By embracing composability, organizations can place themselves to simplify governance and profit from the best advances taking place in our business.
That is an excerpt from DZone’s 2024 Development Report,
Information Engineering: Enriching Information Pipelines, Increasing AI, and Expediting Analytics.









{kind=link}